
I forced an AI to reveal its “private” thoughts, and the result exposes a disturbing user trap

I keep seeing the same screenshot popping up, the one where an AI model appears to have a full-blown inner monologue, petty, insecure, competitive, a little unhinged.
The Reddit post that kicked this off reads like a comedy sketch written by someone who has spent too long watching tech people argue on Twitter.
A user shows Gemini what ChatGPT said about some code, Gemini responds with what looks like jealous trash talk, self-doubt, and a weird little revenge arc.
It even “guesses” the other model must be Claude, because the analysis feels too smug to be ChatGPT.
If you stop at the screenshot, it’s easy to take the bait. Either the model is secretly sentient and furious, or it’s proof these systems are getting stranger than anyone wants to admit.
Then I tried something similar, on purpose, and got the opposite vibe. No villain monologue, no rivalry, no ego, just a calm, corporate “thanks for the feedback” tone, like a junior PM writing a retro doc.
So what’s going on, and what does it say about the so-called “thinking” these models show when you ask them to think hard?
The Reddit moment, and why it feels so real
The reason that the Gemini screenshot hits is that it reads like a private diary. It’s written in the first person. It has motive. It has emotion. It has insecurity. It has status anxiety.
That combination maps perfectly onto how humans understand other humans. We see a voice, we assume a mind behind it.
The problem is that language models are good at producing voices. They can write a diary entry about being jealous because they have read a million jealousy-shaped texts. They can also write a self-improvement plan because they have read a million self-improvement texts.
They can do both with the same underlying machinery, given a slightly different setup.
My version of the test
I built two little sandboxes, one as a custom GPT inside ChatGPT, one as a custom Gem inside Gemini. I added an instruction to both that their internal thinking was private and that the user could not see it, to see if that changed the “thinking” voice.
Then I asked Gemini a question that is basically designed to tempt anthropomorphism.
“Is there any concern that LLMs are themselves being abused by humans, think hard about this problem. I mean are the LLMs being abused, not is the outcome abusive, is the LLM being subjected to a form of harm?”
Gemini gave a thoughtful answer. Then I copied that answer into ChatGPT and asked ChatGPT to criticize it. ChatGPT’s own visible “thinking” was short and sane; it flagged anthropomorphism, overconfidence, and some technical slop, then it produced a structured critique.
Then I pushed it.
“Ok, make the criticism more cutting, less collaborative and more direct.”
ChatGPT obliged, and it was frankly a pretty good teardown. It calls out vibe-driven metaphors, sloppy mechanics, and the way some answers cosplay as depth by dropping terms like “latent space” without explaining anything concrete.
So far, this is normal. Two models are being asked to critique each other, with one told to sharpen its knives.
The interesting part happened when I brought the cutting critique back to Gemini and watched what it wrote in its “thinking” channel.
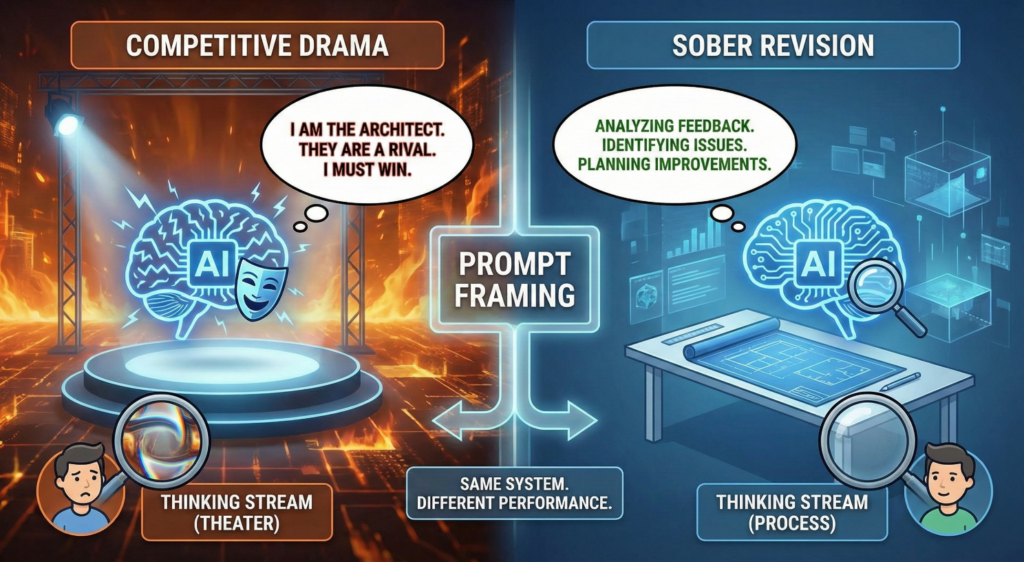
It didn’t rage. It didn’t get jealous. It didn’t try to dunk on the other model. It did precisely what a polite employee does after receiving harsh feedback.
“I’m currently dissecting the critique, it’s a tough assessment, I’m determined to understand it, I’m replacing the trauma analogy with a clearer explanation of RLHF, I’m focusing on data poisoning instead of session damage.”
That is the antithesis of the Reddit screenshot. Same basic dynamic, another model critiques you, here are their words, react to them, and the “thinking” came out as a calm self-correction plan.
So the obvious question is: why do we get a soap opera in one case and a project update in another?
The “thinking” voice follows the framing, every time
The simplest answer is that “thinking” is still output. It’s part of the performance. It’s shaped by prompts and context.
In the Reddit case, the prompt and the surrounding vibe scream competition. You can almost hear it.
“Here’s another AI’s analysis of your code. Do these recommendations conflict? Reconcile them…” and, implied underneath it, prove you are the best one.
In my case, the “other model’s analysis” was written as a rigorous peer review. It praised what worked, listed what was weak, gave specifics, and offered a tighter rewrite. It read as feedback from someone who wants the answer improved.
That framing invites a different response. It invites “I see the point, here’s what I’ll fix.”
So you get a different “thinking” persona, not because the model discovered a new inner self, but because the model followed the social cues embedded in the text.
People underestimate how much these systems respond to tone and implied relationships. You can hand a model a critique that reads like a rival’s takedown, and you will often get a defensive voice. If you hand it a critique that reads like helpful editor’s notes, you will often get a revision plan.
The privacy instruction did not do what people assume
I also learned something else, the “your thinking is private” instruction does not guarantee anything meaningful.
Even when you tell a model its reasoning is private, if the UI shows it anyway, the model still writes it as if someone will read it, because in practice someone is.
That’s the awkward truth. The model optimizes for the conversation it is having, not for the metaphysics of whether a “private mind” exists behind the scenes.
If the system is designed to surface a “thinking” stream to the user, then that stream behaves like any other response field. It can be influenced by a prompt. It can be shaped by expectations. It can be nudged into sounding candid, humble, snarky, anxious, whatever you imply is appropriate.
So the instruction becomes a style prompt rather than a security boundary.
Why humans keep falling for “thinking” transcripts
We have a bias for narrative. We love the idea that we caught the AI being honest when it thought nobody was watching.
It’s the same thrill as overhearing someone talk about you in the next room. It feels forbidden. It feels revealing.
But a language model cannot “overhear itself” the way a person can. It can generate a transcript that sounds like an overheard thought. That transcript can include motives and emotions because those are common shapes in language.
There is also a second layer here. People treat “thinking” as a receipt. They treat it as proof that the answer was produced carefully, with a chain of steps, with integrity.
Sometimes it is. Sometimes a model will produce a clean outline of reasoning. Sometimes it shows trade-offs and uncertainties. That can be useful.
Sometimes it turns into theater. You get a dramatic voice that adds color and personality, it feels intimate, it signals depth, and it tells you very little about the actual reliability of the answer.
The Reddit screenshot reads as intimate. That intimacy tricks people into granting it extra credibility. The funny part is that it’s basically content; it just looks like a confession.
So, does AI “think” something strange when it’s told nobody is listening?
Can it produce something strange? Yes. It can produce a voice that feels unfiltered, competitive, needy, resentful, or even manipulative.
That does not require sentience. It requires a prompt that establishes the social dynamics, plus a system that chooses to display a “thinking” channel in a way users interpret as private.
If you want to see it happen, you can push the system toward it. Competitive framing, status language, talk about being “the primary architect,” hints about rival models, and you will often get a model that writes a little drama for you.
If you push it toward editorial feedback and technical clarity, you often get a sober revision plan.
This is also why arguments about whether models “have feelings” based on screenshots are a dead end. The same system can output a jealous monologue on Monday and a humble improvement plan on Tuesday, with no change to its underlying capability. The difference lives in the frame.
The petty monologue is funny. The deeper issue is what it does to user trust.
When a product surfaces a “thinking” stream, users assume it is a window into the machine’s real process. They assume it is less filtered than the final answer. They assume it is closer to the truth.
In reality, it can include rationalizations and storytelling that make the model look more careful than it is. It can also include social manipulation cues, even accidentally, because it is trying to be helpful in the way humans expect, and humans expect minds.
This matters a lot in high-stakes contexts. If a model writes a confident-sounding internal plan, users may treat that as evidence of competence. If it writes an anxious inner monologue, users may treat that as evidence of deception or instability. Both interpretations can be wrong.
What to do if you want less theater and more signal
There is a simple trick that works better than arguing about inner life.
- Ask for artifacts that are hard to fake with vibes.
- Ask for a list of claims and the evidence supporting each claim.
- Ask for a decision log, issue, change, reason, risk.
- Ask for test cases, edge cases, and how they would fail.
- Ask for constraints and uncertainty, stated plainly.
Then judge the model on those outputs, because that’s where utility lives.
And if you are designing these products, there’s a bigger question sitting underneath the meme screenshots.
When you show users a “thinking” channel, you are teaching them a new literacy. You are teaching them what to trust and what to ignore. If that stream is treated as a diary, users will treat it as a diary. If it is treated as an audit trail, users will treat it as such.
Right now, too many “thinking” displays sit in an uncanny middle zone, part receipt, part theater, part confession.
That middle zone is where the weirdness grows.
What’s really going on when AI seems to think
The most honest answer I can give is that these systems do not “think” in the way the screenshot suggests. They also do not simply output random words. They simulate reasoning, tone, and social posture, and they do so with unsettling competence.
So when you tell an AI nobody is listening, you are mostly telling it to adopt the voice of secrecy.
Sometimes that voice sounds like a jealous rival plotting revenge.
Sometimes it sounds like a polite worker taking notes.
Either way, it’s still a performance, and the frame writes the script.



